您好,欢迎来到陕西网来网去网络科技集团有限公司
官方网站丨 服务热线:029-85796221
服务热线:029-85796221
- 首页
- 产品应用
-
解决方案
 直播卖货APP开发...
直播卖货APP开发...
直播卖货解决方案直播卖货解决方...
 新零售APP开发解...
新零售APP开发解...
新零售解决方案新零售解决方案
 社区物业APP开发...
社区物业APP开发...
社区物业解决方案社区物业解决方...
 社区服务APP开发...
社区服务APP开发...
社区服务解决方案社区服务解决方...
 区县电商APP开发...
区县电商APP开发...
区县电商解决方案区县电商解决方...
 旅游行业APP开发...
旅游行业APP开发...
旅游行业解决方案旅游行业解决方...
 连锁百货APP开发...
连锁百货APP开发...
连锁百货解决方案连锁百货解决方...
 跨境电商APP开发...
跨境电商APP开发...
跨境电商解决方案跨境电商解决方...
 教育行业APP开发...
教育行业APP开发...
教育行业解决方案行业门户解决方...
 行业门户APP开发...
行业门户APP开发...
行业门户解决方案行业门户解决方...
 B2B2C多用户商城...
B2B2C多用户商城...
B2B2C多用户商城B2B2C多用户商城
 020上门APP开发...
020上门APP开发...
020上门解决方案,020上门解决方...
- 技术实施
- 互联网+咨询
- 产品案例
- 技术合伙
- 关于工场
























-

全部服务分类

























 您的预估价格: ? 元
您的预估价格: ? 元









什么是流式大数据,处理技术、平台及应用
时间:2019/01/18
大数据技术的广泛应用使其成为引领众多行业技术进步、促进效益增长的关键支撑技术。根据数据处理的时效性,大数据处理系统可分为批式(batch)大数据和流式(streaming)大数据两类。其中,批式大数据又被称为历史大数据,流式大数据又被称为实时大数据。
举个例子来说:我们把数据当成水库的话,水库里面存在的水就是批式大数据,进来的水是流式大数据
目前主流的大数据处理技术体系主要包括hadoop[1]及其衍生系统。Hadoop技术体系实现并优化了MapReduce[2]框架。Hadoop技术体系主要由谷歌、推特、脸书等公司支持。自2006年首次发布以来, Hadoop技术体系已经从传统的“三驾马车”(HDFS[1]、MapReduce和HBase[3])发展成为包括60多个相关组件的庞大生态系统。在这一生态系统中,发展出了Tez、Spark Streaming[4]等用于处理流式数据的组件。其中,Spark Streaming是构建在Spark基础之上的流式大数据处理框架。与Tez相比,其具有吞吐量高、容错能力强等特点,同时支持多种数据输入源和输出格式。除了Spark开源流处理框架,目前应用较为广泛的流式大数据处理系统还有Storm[5]、Flink[6]等。这些开源的流处理框架已经被应用于部分时效性要求较高的领域,然而在面对各行各业实际而又差异化的需求时,这些开源技术存在着各自的瓶颈。
在互联网/移动互联网、物联网等应用场景中,个性化服务、用户体验提升、智能分析、事中决策等复杂的业务需求对大数据处理技术提出了更高的要求。为了满足这些需求,大数据处理系统必须在毫秒级甚至微秒级的时间内返回处理结果。以国内最大的银行卡收单机构银联商务为例,其日交易量近亿笔,需对旗下540多万个商户进行实时风险监控,在确保这些商户合规开展收单业务的同时,最大限度地保障个人用户的合法权益。这样的高并发、大数据、高实时应用需求给大数据处理系统提出了严峻的挑战。银联商务以前使用的T+1事后风控系统存在风险侦测迟滞高(次日才能发现风险,损害已经造成)、处理时间长(十几个小时之后才能完成风险识别)、无法处理长周期历史数据(只能分析最近几日的流水数据)以及无法支持复杂规则(仅能支持累积求和等简单规则)等重大缺陷。为此,亟须研发全新的事中风控系统,以重点实现低迟滞(在1 min内甄别突发风险)、高实时(100 ms内返回处理结果)、长周期(可处理长达10年以上的历史周期数据)以及支持高复杂度规则(如方差、标准差、K阶中心矩、最大连续统计等)等目标。这一目标可以抽象为一个大数据处理科学问题:如何在一个完整的大数据集上,实现低迟滞、高实时的即席(Ad-Hoc)查询分析处理。
技术解析
现有的大数据处理系统可以分为两类:批处理大数据系统与流处理大数据系统。以Hadoop为代表的批处理大数据系统需先将数据汇聚成批,经批量预处理后加载至分析型数据仓库中,以进行高性能实时查询。这类系统虽然可对完整大数据集实现高效的即席查询,但无法查询到最新的实时数据,存在数据迟滞高等问题。相较于批处理大数据系统,以Spark Streaming、Storm、Flink为代表的流处理大数据系统将实时数据通过流处理,逐条加载至高性能内存数据库中进行查询。此类系统可以对最新实时数据实现高效预设分析处理模型的查询,数据迟滞低。然而受限于内存容量,系统需丢弃原始历史数据,无法在完整大数据集上支持Ad-Hoc查询分析处理。因此,研发具有快速、高效、智能且自主可控特点的流式大数据实时处理技术与平台是当务之急。
实现一个融合批处理和流处理两类系统且对应用透明的系统级方案,需要攻克以下几个技术难点。
(1)复杂指标的增量计算
尽管计数、求和、平均等指标能够依靠查询结果合并实现,然而方差、标准差、熵等大部分复杂指标无法依靠简单合并完成查询结果的融合。再者,当查询涉及热点数据维度及长周期时间窗口的复杂指标时,多次重新计算会带来巨大的计算开销。
(2)基于分布式内存的并行计算
采用粗放的调度策略(例如约定在每天的固定时间将流数据导入批处理系统)会造成内存资源的极大浪费,亟须研究实现一种细粒度的基于进度实时感知的融合存储策略,以极大地优化和提升融合系统的内存使用效率。
(3)多尺度时间窗口漂移的动态数据处理
来自业务系统的数据查询请求会涉及多种尺度的时间窗口,如“最近5笔刷卡交易的金额”“最近10 min内密码重试次数”“过去10年的月均交易额”等。每次查询请求都重新计算结果会对系统性能造成极大的影响,亟须研究实现一种支持多种时间窗口尺度(数秒到数十年)、多种窗口漂移方式(数据驱动、系统时钟驱动)的动态数据实时处理方法,以快速响应来自业务系统的即席查询请求。
(4)高可用、高可扩展的内存计算
基于内存介质能够大大提升数据分析及处理能力,然而由于其易挥发的特性,一般需要采用多副本的方式来实现基于内存的高可用方案,这使得“如何确保不同副本的一致性”成为一个待解决的问题。此外,在集群内存不足或者部分节点失效时,“如何让集群在不间断提供服务的同时重新平衡”同样是一个待解决的技术难题。亟须研究分布式多副本一致性协议以及自平衡的智能分区算法,以进一步提升流处理集群的可用性以及可扩展性。
“流立方”流式大数据实时处理技术在上述领域取得了一系列突破,该技术提供基于时间窗口漂移的动态数据快速处理,支持计数、求和、平均、最大、最小、方差、标准差、K阶中心矩、递增/递减、最大连续递增/递减、唯一性判别、采集、过滤等多种分布式统计计算模型,并且实现了复杂事件、上下文处理等实时分析处理模型集的高效管理技术。
平台纵览
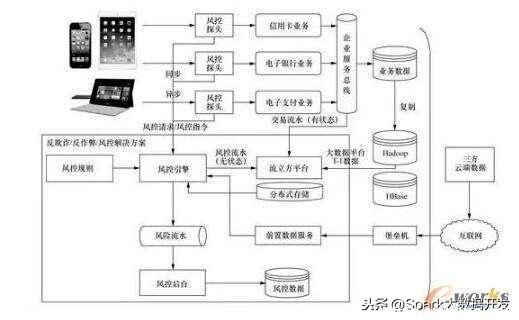
基于“流立方”流式大数据实时处理技术,研发了“流立方”流式大数据实时处理平台。其应用框架如图1所示,具有良好的灵活性和适应性。平台的数据装载模块负责从具体业务系统中接入实时流数据,数据抽取模块负责批量抽取历史数据,模型装载模块负责将分析处理模型集中的计算模型和脚本加载到平台中。当收到业务系统发出的实时查询请求时,“流立方”平台能够根据分析处理模型在完整大数据集上实时计算出相应的指标,并进行判断,将结果反馈给业务系统。
 专注移动互联网+
专注移动互联网+ 7*8小时一对一服务
7*8小时一对一服务 免费提供解决方案
免费提供解决方案 10000+客户推荐
10000+客户推荐

售前/售后咨询
029-85796221
13363901706(微信同号)
北京市海淀区中关村软件园中区C座
郑州市高新区863软件园1号楼C座
